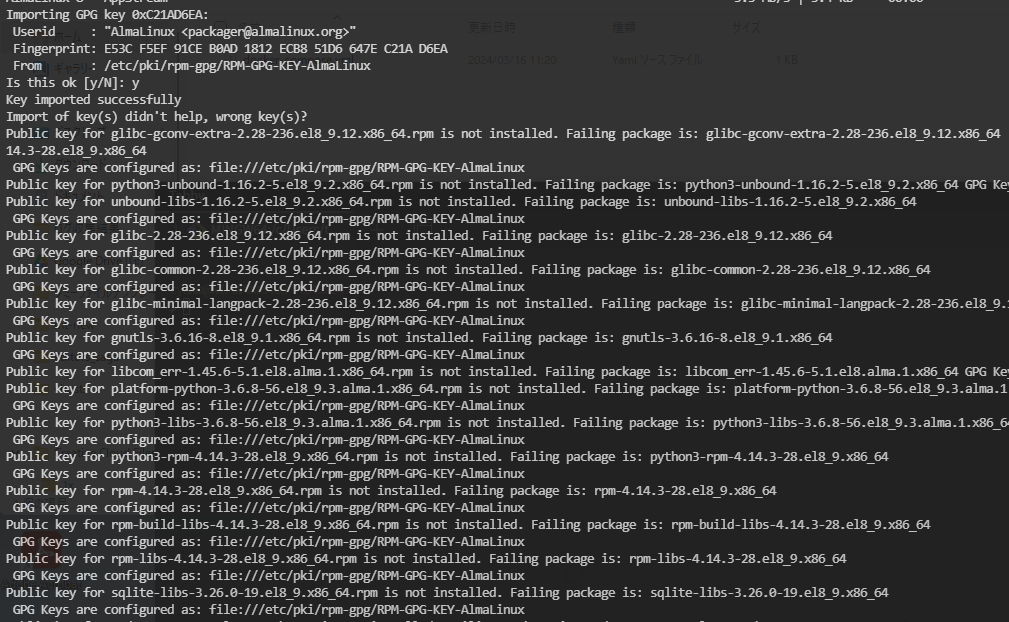
dnf updateやdnf installなどでPublic keyに関するエラーが出るときの対処方法
kurumin
プログラミングのーと

#!/bin/bash
# ベースURLを定義
BASE_URL="https://www.hogehoge.com"
# 保存ディレクトリを定義
SAVE_DIR=~/wget_hogehoge
# パスリストファイルを読み込んで、各パスに対してwgetコマンドを実行
while IFS= read -r path; do
# キャリッジリターンを取り除く
clean_path=$(echo "$path" | tr -d '\r')
# wgetコマンドを実行
wget -x -np -nH -P "$SAVE_DIR" -A html --no-check-certificate --wait=3 --limit-rate=10m -e robots=off "${BASE_URL}${clean_path}"
done < /var/mysql/paths.txt
